

بهترین پایگاه داده برای Node.js چیست؟
فهرست مطالب
- معرفی
- پایگاه های داده SQL و NoSQL
- زبان
- مقیاس پذیری
- ساختار و نوع داده
- درخواست ها
- حمایت کردن
- مقایسه پایگاه های داده SQL و NoSQL
- پایگاه های داده SQL برای Node.js – مقایسه
- انواع داده ها
- ویژگی های ذخیره سازی داده ها
- پشتیبانی استاندارد SQL
- کارایی
- محبوبیت
- انتخاب بهترین پایگاه داده SQL برای Node.js
- پایگاه های داده NoSQL برای Node.js – مقایسه
- انواع داده ها
- همانند سازی
- نمایه سازی
- مقیاس پذیری
- محبوبیت
- انتخاب بهترین پایگاه داده NoSQL برای Node.js
- نتیجه
معرفی
Node.js توسط حدود 2٪ از تمام وب سایت ها استفاده می شود – یعنی حدود 4 میلیون صفحه از مجموع 2 میلیارد موجود در شبکه سطحی. Node پایه و اساس برخی از محبوب ترین پلتفرم های آنلاین مانند Twitter، Netflix، Spotify، Github و غیره است.
انتخاب بهترین پایگاه داده برای پروژه Node.js یکی از اولین مواردی است که باید قبل از شروع توسعه در نظر بگیرید. Node.js معمولاً از همه انواع پایگاه داده پشتیبانی می کند، صرف نظر از SQL یا NoSQL. با این وجود، انتخاب پایگاه داده باید بر اساس پیچیدگی و اهداف برنامه شما انجام شود. در این مقاله نگاهی دقیقتر به پایگاههای داده SQL و NoSQL و همچنین نمونههای کاربردی آنها خواهیم داشت.
پایگاه های داده SQL و NoSQL
تمام محاسبات کامپیوتری مربوط به پردازش داده ها است. آنها می توانند ساختارمند و بدون ساختار باشند. اولی ها در پایگاه های داده قرار می گیرند، جایی که توضیحات آنها همراه با اطلاعات ذخیره می شود. هنگام صحبت در مورد پایگاه های داده اغلب می توانید با اصطلاحات “SQL” و “NoSQL” برخورد کنید.
SQL یک تکنیک پردازشی است که برای پردازش پایگاه داده های رابطه ای و غیر رابطه ای (NoSQL) استفاده می شود.
اصطلاح “رابطه ای” از جبر گرفته شده است. در پایگاه های داده، به این معنی است که داده های پایگاه داده رابطه ای در قالب جداول و ردیف ذخیره می شوند. پایگاه داده های غیر رابطه ای اطلاعات را در مجموعه هایی از اسناد JSON ذخیره می کنند.
پایگاه داده های رابطه ای از SQL استفاده می کنند که مخفف عبارت “Structured Query Language” است. ساختار چنین پایگاههای اطلاعاتی به شما امکان میدهد اطلاعات جداول مختلف را با استفاده از کلیدهای خارجی (یا شاخصها) پیوند دهید، که برای شناسایی منحصر به فرد هر قطعه اتمی داده در هر جدول استفاده میشود. سایر جداول می توانند به این کلید خارجی مراجعه کنند تا رابطه ای بین قطعات داده و قطعاتی که توسط این کلید خارجی به آنها اشاره شده است ایجاد کنند.
چرا به پایگاه های داده غیر رابطه ای نیاز داریم؟ مزیت اصلی آنها سطح بالای امنیت و توانایی دور زدن محدودیت های سخت افزاری است.
حال بیایید نگاهی به تفاوت ها و شباهت های بین پایگاه های داده SQL و NoSQL بیندازیم.
زبان
شهری را تصور کنید که در آن همه به یک زبان صحبت می کنند. این زبان در تمامی اشکال ارتباطی مورد استفاده قرار می گیرد و تمامی فرآیندهای تجاری بر روی آن ساخته می شوند. ساکنان این شهر یکدیگر را درک می کنند و تنها از طریق این زبان دنیای اطراف خود را کشف می کنند. اگر زبان در یک جا به طور ناگهانی تغییر کند، بقیه گیج خواهند شد.
حالا شهر دیگری را تصور کنید که در آن همه در خانه به زبان های مختلف صحبت کنند. هر کس به روش های مختلف با جهان تعامل دارد، هیچ راه “جهانی” برای درک و هیچ سازمان پایدار ارتباطات وجود ندارد. اگر کسی چیزی را تغییر دهد، بر دیگری تأثیر نخواهد گذاشت.
این مثال به نشان دادن یکی از تفاوت های اصلی بین پایگاه های داده SQL (رابطه ای) و NoSQL (غیر رابطه ای) کمک می کند.
پایگاه داده های رابطه ای از یک زبان پرس و جو ساخت یافته برای پردازش و دستکاری داده ها استفاده می کنند. از یک طرف، این بسیار راحت است: SQL یکی از متنوع ترین و رایج ترین گزینه های زبانی است، بنابراین انتخاب مطمئنی است. همچنین، برای پرس و جوهای پیچیده مناسب است. از طرف دیگر محدودیت های خاصی در این زبان وجود دارد. قبل از شروع کار با SQL، باید از طرحواره های از پیش تعریف شده برای تعریف ساختار داده استفاده کنید. علاوه بر این، تمام داده ها باید ساختار یکسانی داشته باشند. مانند مثال اول که گفته شد: تغییر در ساختار می تواند منجر به عوارض شود و کل سیستم را از بین ببرد.
در مقابل، پایگاه های داده غیر رابطه ای دارای طرحواره های انعطاف پذیر برای داده های بدون ساختار هستند. میتوان آن را به روشهای مختلفی ذخیره کرد: در ستونها، اسناد، نمودارها یا بهعنوان ذخیرهسازی مقدار کلید.
این انعطاف پذیری به موارد زیر اجازه می دهد:
شما می توانید اسناد را بدون تعریف ساختار آنها از قبل ایجاد کنید.
هر سند می تواند ساختار منحصر به فرد خود را داشته باشد.
نحو ممکن است در پایگاه داده های مختلف متفاوت باشد.
می توانید فیلدهای جدیدی را در فرآیند کار اضافه کنید.
SQL از یک زبان پرس و جو ساخت یافته جهانی برای تعریف و دستکاری داده ها استفاده می کند. این محدودیتهای خاصی را تحمیل میکند: قبل از شروع پردازش، دادهها باید در جداول قرار گرفته و شرح داده شوند.
مقیاس پذیری
در بیشتر موارد، پایگاه داده های SQL را می توان به صورت عمودی مقیاس کرد، به این معنی که امکان افزایش بار روی هر سرور جداگانه، افزایش قدرت CPU، RAM و دیسک وجود دارد. اما پایگاه داده های NoSQL را می توان به صورت افقی مقیاس بندی کرد. به این معنی که بار با تقسیم داده ها یا افزودن سرورهای بیشتر توزیع می شود. یکی مانند افزودن طبقات بیشتر به یک ساختمان و دیگری مانند افزودن ساختمان های بیشتر به یک محله است. دومی به سیستم اجازه می دهد بزرگتر و قدرتمندتر شود. به همین دلیل است که NoSQL معمولاً برای پایگاه های داده بزرگ یا اغلب در حال تغییر انتخاب می شود.
ساختار و نوع داده
پایگاه داده های رابطه ای داده های ساختار یافته را ذخیره می کنند که معمولاً اشیاء را در دنیای واقعی نشان می دهد. به عنوان مثال، می تواند اطلاعاتی در مورد یک شخص یا در مورد محتویات یک سبد خرید باشد. این داده ها در جداول دسته بندی می شوند که فرمت آنها در مرحله طراحی فروشگاه تنظیم شده است.
پایگاه داده های غیر رابطه ای ساختار متفاوتی دارند. به عنوان مثال، پایگاه های داده مدار مدار، اطلاعات را در قالب ساختارهای داده سلسله مراتبی ذخیره می کنند. در اینجا می توانیم اشیایی با مجموعه ای دلخواه از ویژگی ها داشته باشیم. آنچه در یک پایگاه داده رابطه ای به چندین جدول به هم پیوسته تقسیم می شود را می توان در یک پایگاه داده غیر رابطه ای به عنوان یک موجودیت انتگرال واحد ذخیره کرد.
درخواست ها
صرف نظر از مجوز، RDBMS از استانداردهای SQL استفاده می کند، بنابراین می توانید با استفاده از زبان SQL داده ها را از آنها دریافت کنید.
پایگاه داده های NoSQL از فرمت پرس و جو رایج استفاده نمی کنند، بنابراین هر راه حل NoSQL از سیستم پرس و جو خود استفاده می کند.
حمایت کردن
DBMS های رابطه ای سابقه ای طولانی در پشت خود دارند. آنها بسیار محبوب هستند و راه حل های رایگان و پولی را ارائه می دهند. یافتن پاسخ برای یک مشکل سیستم رابطه ای بسیار ساده تر از یک مشکل با یک سیستم NoSQL است، به خصوص اگر راه حل در ماهیت خود پیچیده باشد.
مقایسه پایگاه های داده SQL و NoSQL
| SQL | NoSQL | |
| زبان پرس و جو | ساختار یافته | غیر اعلامی |
| تایپ کنید | مبتنی بر جدول | مبتنی بر سند، جفت های کلید-مقدار، نمودار |
| طرحواره | از پیش تعریف شده | پویا |
| مقیاس پذیری | عمودی | افقی |
| مثال ها | MySQL، PostgreSQL، SQLite | MongoDB، Redis، Apache Cassandra |
| ذخیره سازی داده ها | مناسب ترین برای مدل سلسله مراتبی | مناسب برای مدل سلسله مراتبی در جفت کلید-مقدار |
| متن باز | ترکیبی از تجاری و منبع باز | متن باز |
| سخت افزار | تخصصی | کالا |
| نوع ذخیره سازی | SAN، RAID و غیره | HDD های استاندارد، JBOD |
پایگاه های داده SQL برای Node.js – مقایسه

عمومی
MySQL
MySQL امروزه یکی از پرکاربردترین سیستم های مدیریت پایگاه داده است. 16.65٪ از کل استفاده از پایگاه داده را به خود اختصاص می دهد ، که تنها توسط Oracle با 30.2٪ پیشی گرفته است.
این سیستم برای کار با حجم نسبتاً زیادی از اطلاعات استفاده می شود. با این حال، MySQL برای پروژه های کوچک و بزرگ ایده آل است. یک ویژگی مهم سیستم رایگان بودن آن است.
ببینید چگونه از MySQL برای Node.js در پروژههای مختلف، از جمله LMS ، کیف پول دیجیتال ، پلتفرم بازاریابی ، برنامه رتبهبندی CS:GO و راهکار EdTech مبتنی بر هوش مصنوعی استفاده کردیم .
PostgreSQL
PostgreSQL یک سیستم مدیریت پایگاه داده شی رابطه ای رایگان و محبوب است. PostgreSQL مبتنی بر زبان SQL است و از ویژگی های متعددی پشتیبانی می کند، مانند:
همانندسازی ناهمزمان؛
انواع تعریف شده توسط کاربر؛
معاملات تو در تو؛
کنترل همزمان چند نسخه؛
یکپارچگی مرجع برای کلیدهای خارجی؛
وراثت جدول؛
و بیشتر.
ما از PostgreSQL در کنار Node.js برای ساختن یک برنامه بهداشتی هوشمند از راه دور استفاده کرده ایم. برای کسب اطلاعات بیشتر، این مطالعه موردی را بررسی کنید .
SQLite
پایگاه داده به راحتی در برنامه ها قابل جاسازی است. از آنجایی که این سیستم مبتنی بر فایل است، در مقایسه با DBMS شبکه، طیف نسبتاً وسیعی از ابزارها را برای کار با آن فراهم می کند. هنگام کار با این DBMS، به جای پورت ها و سوکت ها در DBMS شبکه، درخواست ها مستقیماً به فایل ها (جایی که داده ها ذخیره می شوند) ارسال می شود. SQLite همچنین به لطف فناوری های ارائه دهنده کتابخانه بسیار سریع و قدرتمند است.
انواع داده ها
MySQL
MySQL از انواع داده های زیر پشتیبانی می کند:
TINYINT: عدد صحیح بسیار کوچک.
SMALLINT: عدد صحیح کوچک.
MEDIUMINT: عدد صحیح کامل با اندازه متوسط.
INT: عدد صحیح کامل با اندازه عادی.
BIGINT: یک عدد صحیح بزرگ.
FLOAT: عدد ممیز شناور امضا شده تک دقیق.
DOUBLE, DOUBLE PRECISION, REAL: امضا شده با دقت دو برابر شماره ممیز شناور.
اعشاری، عددی: عدد ممیز شناور امضا شده.
تاریخ: تاریخ;
DATETIME: ترکیبی از تاریخ و زمان.
TIMESTAMP: تمبر زمان.
زمان: زمان؛
سال: یک سال در قالب YY یا YYYY.
CHAR: رشتهای با اندازه ثابت، با فاصلههای تا حداکثر طول به سمت راست پر شده است.
VARCHAR: رشته طول متغیر.
TINYBLOB، TINYTEXT: داده های باینری یا متنی با حداکثر طول 255 کاراکتر.
BLOB، TEXT: داده های باینری یا متنی با حداکثر طول 65535 کاراکتر.
MEDIUMBLOB، MEDIUMTEXT: متن یا داده های باینری.
LONGBLOB، LONGTEXT: متن یا داده های باینری حداکثر 4294967295 کاراکتر.
ENUM: شمارش
SET: مجموعه ها.
PostgreSQL
انواع فیلدهای پشتیبانی شده در Postgresql کاملاً متفاوت هستند، اما به شما امکان می دهند دقیقاً همان داده را بنویسید:
bigint: عدد صحیح 8 بایتی امضا شده.
bigserial: یک عدد صحیح 8 بایتی که به طور خودکار در حال رشد است.
بیت: رشته باینری با طول ثابت.
bit variing: یک رشته باینری با طول های مختلف.
بولی: پرچم;
جعبه: یک مستطیل در یک هواپیما؛
بایت: داده های باینری
کاراکتر متغیر: یک رشته نماد با طول ثابت.
کاراکتر: یک رشته نماد با طول های مختلف.
cidr: آدرس شبکه IPv4 یا IPv6.
دایره: دایره در یک هواپیما;
تاریخ: تاریخ در تقویم؛
دقت دوگانه: تعداد ممیز شناور دقت مضاعف.
inet: آدرس IPv4 یا IPv6 اینترنت؛
عدد صحیح: عدد صحیح 4 بایتی امضا شده.
interval: فاصله زمانی;
خط: یک خط مستقیم بی نهایت در یک صفحه;
lseg: بخش خط;
macaddr: آدرس مک.
پول: ارزش پولی؛
مسیر: مسیر هندسی در هواپیما.
نقطه: نقطه هندسی در یک صفحه;
چند ضلعی: چند ضلعی در یک صفحه;
واقعی: عدد ممیز شناور تک دقیق.
smallint: عدد صحیح دو بایتی.
سریال: عدد صحیح چهار بیتی به طور خودکار افزایش می یابد.
متن: رشته الگوی طول متغیر;
زمان: زمان روز؛
مهر زمانی: تاریخ و زمان؛
tsquery: عبارت جستجوی متنی.
tsvector: سند جستجوی متن.
uuid: شناسه منحصر به فرد.
xml: داده های XML.
SQLite
کلاس های ذخیره سازی:
NULL – مقدار یک مقدار NULL است.
INTEGER – مقدار یک عدد صحیح امضا شده است که بسته به بزرگی مقدار در 1، 2، 3، 4، 6 یا 8 بایت ذخیره می شود.
REAL – مقدار یک مقدار ممیز شناور است که به عنوان یک عدد ممیز شناور IEEE 8 بایتی ذخیره می شود.
TEXT – مقدار یک رشته متنی است که با استفاده از رمزگذاری پایگاه داده (UTF-8، UTF-16BE، یا UTF-16LE) ذخیره شده است.
BLOB – یک مقدار بلوکی از داده است که دقیقاً همانطور که وارد شده است ذخیره می شود.
نوع ادغام:
TEXT – این ستون تمام داده ها را با استفاده از کلاس های ذخیره سازی NULL، TEXT یا BLOB ذخیره می کند.
NUMERIC – این ستون می تواند حاوی مقادیری باشد که از هر پنج کلاس ذخیره سازی استفاده می کنند.
INTEGER – عملکردی مشابه یک ستون با قرابت NUMERIC دارد، با استثنا در عبارت CAST.
REAL – مانند یک ستون با قرابت NUMERIC رفتار می کند، با این تفاوت که مقادیر صحیح را به نمایش ممیز شناور می دهد.
NONE – ستونی با قرابت NONE یک کلاس ذخیره سازی را بر دیگری ترجیح نمی دهد و هیچ تلاشی برای اجبار داده ها از یک کلاس ذخیره سازی به کلاس دیگر انجام نمی شود.
ویژگی های ذخیره سازی داده ها
MySQL
MySQL یک پایگاه داده رابطه ای است که در آن از موتورهای مختلفی برای ذخیره داده ها در جداول استفاده می شود. با این حال، روند کار با موتورها در خود سیستم پنهان است. موتور نه بر نحو درخواست ها و نه بر اجرای آنها تأثیر می گذارد. موتورهای اصلی پشتیبانی شده MyISAM، InnoDB، MEMORY و Berkeley DB هستند. آنها در نحوه نوشتن داده ها بر روی دیسک و همچنین در روش های دریافت کننده آنها با یکدیگر تفاوت دارند.
PostgreSQL
PostgreSQL یک پایگاه داده شی-رابطه ای است که تنها بر روی یک موتور – یک موتور ذخیره سازی – اجرا می شود. همه جداول به عنوان اشیا نمایش داده می شوند و می توانند به ارث برده شوند. تمام اقدامات با جداول با استفاده از توابع عینی گرا انجام می شود. همه داده ها بر روی دیسک، در فایل های مرتب شده ویژه ذخیره می شوند، اما ساختار این فایل ها و رکوردهای موجود در آنها بسیار متفاوت است.
SQLite
SQLite یک پایگاه داده تعبیه شده است. کلمه “Embedded” به این معنی است که SQLite از پارادایم مشتری-سرور استفاده نمی کند. به عبارت دیگر، موتور SQLite یک فرآیند کار جداگانه نیست که برنامه با آن تعامل داشته باشد، بلکه کتابخانه ای است که برنامه با آن مرتبط است – موتور به بخشی جدایی ناپذیر از برنامه تبدیل می شود. بنابراین، فراخوانی تابع (API) کتابخانه SQLite به عنوان یک پروتکل تبادل استفاده می شود. این رویکرد سربار را کاهش می دهد، زمان پاسخ را کاهش می دهد و برنامه را ساده می کند. SQLite کل پایگاه داده (شامل تعاریف، جداول، شاخصها و دادهها) را در یک فایل استاندارد روی رایانهای که برنامه روی آن اجرا میشود، ذخیره میکند.
پشتیبانی استاندارد SQL
MySQL
MySQL از تمام ویژگی های جدید استاندارد SQL پشتیبانی نمی کند. توسعه دهندگان این مسیر توسعه را برای استفاده آسان MySQL انتخاب کردند. این شرکت سعی می کند استانداردها را رعایت کند، اما نه به قیمت سادگی. اگر یک ویژگی بتواند قابلیت استفاده را بهبود بخشد، توسعهدهندگان میتوانند بدون توجه به استاندارد آن را به عنوان یک افزونه پیادهسازی کنند.
PostgreSQL
PostgreSQL یک پروژه متن باز است. این توسط تیمی از علاقه مندان توسعه یافته است و توسعه دهندگان سعی می کنند تا حد امکان از استاندارد SQL پیروی کنند و در عین حال تمام جدیدترین استانداردها را پیاده سازی کنند. اما همه اینها منجر به از بین رفتن سادگی می شود. PostgreSQL بسیار پیچیده است، و به همین دلیل، به اندازه MySQL محبوب نیست.
SQLite
SQLite تلاش می کند تا بر اساس اصل “حداقل اما کامل” زندگی کند. برخی از ویژگی های پیچیده را پشتیبانی نمی کند، اما عملکرد آن از بسیاری جهات با SQL 92 مطابقت دارد. و برخی از ویژگی های خود را معرفی می کند که بسیار راحت هستند، البته غیر استاندارد.
ویژگی های زیر پشتیبانی نمی شوند:
پیوستن راست و کامل بیرونی. فقط LEFT OUTER JOIN اجرا می شود.
ALTER TABLE تا حدی پیاده سازی شده است. فقط RENAME TABLE و ADD COLUMN موجود است.
پشتیبانی جزئی از ماشه فقط برای هر ردیف محرک ها در دسترس هستند.
ضبط در VIEWS. در SQLite، VIEWS فقط خواندنی است. تا حدی از طریق ماشه دور زده شده است.
به دلیل پیاده سازی پایگاه داده به صورت یک فایل و خارج شدن از مفهوم سرویس گیرنده-سرور، از قابلیت GRANT و ReEVOKE استفاده نمی شود.
کلیدهای خارجی به طور پیش فرض غیرفعال هستند. این برای سازگاری با عقب است.
کارایی
MySQL
در بیشتر موارد، یک جدول InnoDB برای سازماندهی کار با پایگاه داده در MySQL استفاده می شود. این جدول یک درخت B با شاخص است. شاخص ها به شما امکان می دهند داده ها را خیلی سریع از دیسک خارج کنید، به این معنی که عملیات دیسک کمتری انجام شود. اما اسکن یک درخت مستلزم یافتن دو شاخص است که در حال حاضر کند است.
PostgreSQL
تمام اطلاعات هدر جدول PostgreSQL در RAM است. شما نمی توانید جدولی ایجاد کنید که خارج از حافظه باشد. رکوردهای جدول بر اساس شاخص مرتب شده اند، بنابراین می توانید آنها را خیلی سریع بازیابی کنید. برای راحتی بیشتر، می توانید چندین شاخص را در یک جدول اعمال کنید.
به طور کلی، PostgreSQL سریعتر است، به استثنای عملیاتی که شامل استفاده از کلیدهای اصلی است.
SQLite
مانند MySQL، شاخصها در SQLite بر اساس الگوریتم درخت B ساخته میشوند. چیزی که آن را منحصر به فرد می کند این است که SQLite برای پایگاه داده های کوچک کاملاً مناسب است. با رشد پایگاه داده، نیاز به حافظه در هنگام استفاده از SQLite نیز افزایش می یابد. بهینه سازی کمی برای عملکرد SQLite وجود دارد.
برای بهبود عملکرد پایگاه داده با شاخص ها، بهتر است از:
استفاده از آنها روی میزهای کوچک؛
استفاده از آنها در جداول با بهروزرسانیها یا درجهای دستهای مکرر و بزرگ.
استفاده از آنها برای ستون هایی با مقدار زیادی از مقادیر NULL.
محبوبیت
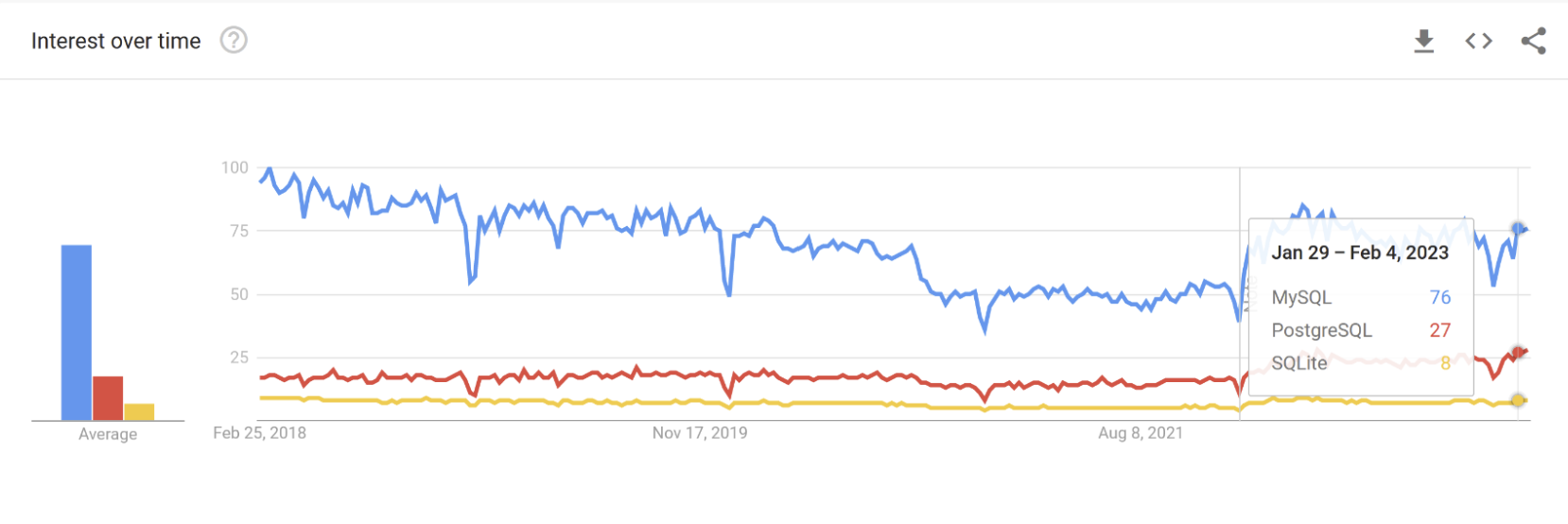
در سال گذشته، MySQL محبوب ترین پایگاه داده در میان موارد ذکر شده در بالا بود. PostgreSQL در جایگاه دوم قرار گرفت و SQLite در جایگاه آخر قرار گرفت.
انتخاب بهترین پایگاه داده SQL برای Node.js
| شاخص | MySQL | PostgreSQL | SQLite |
| انواع داده ها | TINYINT، SMALLINT، MEDIUMINT، INT، BIGINT، FLOAT، DOUBLE، DOUBLE PRECISION، REAL، اعشاری، عددی، DATE، DATETIME، TIMESTAMP، TIME، YEAR، CHAR، VARCHAR، TINYOBTUMBLME, TINYBLMETUMTUMTUMT, TINYOBTUMBLMET لنگ بلند , LONGTEXT, ENUM, SET. | bigint, bigserial, bit, bit variing, boolean, box, byte, character متغیر, نویسه, cidr, دایره, تاریخ, دقت مضاعف, inet, عدد صحیح, بازه, خط, lseg, macaddr, پول, مسیر, نقطه, چند ضلعی, واقعی , smallint, serial, text, time, timestamp, tsquery, tsvector, uuid, xml. | کلاس های ذخیره سازی: NULL، Integer، REAL، TEXT، BLOB. نوع ادغام: TEXT، NUMERIC، Integer، REAL، NONE. |
| ویژگی های ذخیره سازی داده ها | موتورهای مختلفی که در سیستم مخفی هستند برای ذخیره داده ها در جداول استفاده می شوند. آنها روی نحو درخواست ها تأثیری ندارند. آنها در نحوه نوشتن داده ها روی دیسک با یکدیگر تفاوت دارند. | فقط یک موتور ذخیره سازی استفاده می شود. | تمام داده ها بر روی دیسک، در فایل های مرتب شده ویژه با ساختارهای مختلف ذخیره می شوند. |
| پشتیبانی استاندارد SQL | از همه ویژگی های جدید پشتیبانی نمی کند. در صورت نیاز، می توان آنها را به عنوان یک افزونه پیاده سازی کرد. | توسعه دهندگان سعی می کنند تا حد امکان از استاندارد SQL پیروی کنند و تمام جدیدترین استانداردها را پیاده سازی کنند. | از بسیاری جهات، با SQL 92 مطابقت دارد. ویژگی های زیر پشتیبانی نمی شوند: RIGHT و FULL OUTER JOIN. فقط LEFT OUTER JOIN اجرا می شود. ALTER TABLE تا حدی پیاده سازی شده است. فقط RENAME TABLE و ADD COLUMN موجود است. پشتیبانی جزئی از ماشه فقط برای هر ردیف محرک ها در دسترس هستند. ضبط در VIEWS. آنها فقط خواندنی هستند. تا حدی از طریق ماشه دور زده شده است. از قابلیت های GRANT و ReEVOKE استفاده نمی شود. کلیدهای خارجی به طور پیش فرض غیرفعال هستند. |
| کارایی | به عنوان یک درخت B با شاخص هایی کار می کند که به شما امکان می دهد داده ها را خیلی سریع از دیسک خارج کنید، که به عملیات دیسک کمتری نیاز دارد. | اطلاعات هدر در رم است. برای بهبود عملکرد می توان از شاخص ها استفاده کرد. شاخص های متعددی را می توان اعمال کرد. | |
| محبوبیت | محبوب ترین | دومین محبوب ترین | کم محبوب ترین |
پایگاه های داده NoSQL برای Node.js – مقایسه

عمومی
MongoDB
MongoDB یک سیستم مدیریت پایگاه داده مبتنی بر سند است که نیازی به توضیح طرح جدول ندارد. این سیستم که یکی از نمونه های کلاسیک سیستم های NoSQL در نظر گرفته می شود، از اسناد JSON مانند و یک طرح پایگاه داده استفاده می کند. نوشته شده در C ++.
بسیاری MongoDB را پایگاه داده NoSQL «پیشفرض» برای Node میدانند، زیرا به خوبی با فریمورک ادغام میشود. اما گفتن این که همیشه بهترین انتخاب است، یک تصور اشتباه است – سایر پایگاه های داده NoSQL با درایورهای مناسب به خوبی کار می کنند.
Mongo همچنین به طور گسترده ای برای توسعه میکروسرویس ها استفاده می شود. در این مقاله درباره ساخت میکروسرویس با Node.js بیشتر بیاموزید .
Redis
Redis یک پایگاه داده کلید-مقدار NoSQL است. Redis داده ها را در RAM ذخیره می کند که یکی از ویژگی های کلیدی این حافظه است. این باعث می شود آن را بسیار سریع، اما نه قابل اعتماد. Redis به صورت دورهای تمام دادهها را روی دیسک پاک میکند، اما اگر سرور بین افزودن اطلاعات جدید و ذخیره آن در دیسک از کار بیفتد، دادهها از بین خواهند رفت. به همین دلیل، Redis اغلب نه بهعنوان ذخیرهسازی اصلی، بلکه بهعنوان حافظه پنهان، سیستم مدیریت جلسه، یا برای حل مشکل دیگری که از دست دادن دادهها مانع از معامله نیست، استفاده میشود.
Apache Cassandra
آپاچی کاساندرا یک DBMS توزیع شده با تحمل خطا غیر رابطه ای است. این برای ایجاد ذخیره سازی بسیار مقیاس پذیر و قابل اعتماد از مقادیر عظیمی از داده های ارائه شده در قالب یک هش طراحی شده است. پروژه مبتنی بر جاوا توسط فیس بوک در سال 2008 توسعه یافت و سپس در سال 2009 به بنیاد نرم افزار آپاچی اهدا شد. این DBMS یک راه حل ترکیبی NoSQL است زیرا مدل ذخیره سازی ColumnFamily را با مفهوم کلید ارزش ترکیب می کند.
انواع داده ها
MongoDB
عدد صحیح – مقادیر عدد صحیح را ذخیره کنید. بسته به سرور، می تواند 32 بیتی یا 64 بیتی باشد.
دو – ذخیره مقادیر ممیز شناور.
بولی – ذخیره مقادیر بولی (درست/نادرست)؛
رشته – رشته های کاراکتر را ذخیره کنید. MongoDB از رمزگذاری UTF-8 استفاده می کند.
آرایه ها – آرایه های مقادیر را با یک کلید ذخیره می کند.
شی – اسناد تعبیه شده؛
نماد – به همان روش String استفاده می شود، اما معمولاً برای زبان هایی که از کاراکترهای خاص استفاده می کنند رزرو می شود.
Null – ذخیره یک مقدار Null.
مهر زمانی – تاریخ و زمان ذخیره؛
حداقل/حداکثر – مقادیر را با بزرگترین و کوچکترین عناصر BSON (Binary JSON) مقایسه کنید.
شناسه شی – شناسه سند را ذخیره کنید.
عبارت منظم – ذخیره عبارات منظم.
کد – ذخیره کد جاوا اسکریپت در یک سند.
داده های باینری – ذخیره داده های باینری.
تاریخ – تاریخ یا زمان فعلی را در قالب یونیکس ذخیره کنید.
Redis
رشته ها – با استفاده از کتابخانه رشته پویا C پیاده سازی شده اند.
لیست ها – لیست های پیوندی؛
مجموعه ها و هش ها – جداول هش.
مجموعه های مرتب شده – از لیست ها رد شوید (نوع خاصی از درخت متعادل).
Apache Cassandra
در اینجا انواع داده ها به 3 گروه تقسیم می شوند:
انواع داده های داخلی؛
مجموعه ها؛
توسط کاربر ایجاد شده است.
انواع داده های داخلی:
ascii – رشته ها (رشته های ASCII)؛
bigint – اعداد صحیح بزرگ (اعداد 64 بیتی)؛
blob – BLOB (بایت)؛
بولی – مقادیر بولی (درست/نادرست)
شمارنده – اعداد صحیح (ستون)؛
اعشاری – اعداد صحیح، اعداد ممیز شناور (اعداد دقیق ممیز شناور)؛
دو عدد صحیح (اعداد 64 بیتی IEEE-754)؛
float – اعداد صحیح، اعداد ممیز شناور (اعداد 32 بیتی IEEE-754)؛
inet – رشته ها (آدرس IP، IPv4 یا IPv6)؛
int – اعداد صحیح (اعداد صحیح امضا شده 32 بیتی)؛
متن – رشته ها (رشته کدگذاری شده UTF-8)؛
مهر زمان – اعداد صحیح، رشته ها (زمان)؛
timeuuid – شناسه منحصر به فرد (UUID نوع 1)؛
uuid – شناسه منحصر به فرد (UUID نوع 1 یا 4)؛
varchar – رشته ها (رشته رمزگذاری شده UTF-8)؛
varint – اعداد صحیح (عدد صحیح دقیق).
مجموعه ها:
لیست – مجموعه ای از یک یا چند عنصر مرتب شده؛
نقشه – مجموعه ای از جفت های کلید-مقدار؛
مجموعه – مجموعه ای از یک یا چند عنصر.
همانند سازی
MongoDB
سیستم ذخیره سازی در MongoDB یک مجموعه ماکت را نشان می دهد. این مجموعه دارای یک گره اولیه است و همچنین می تواند مجموعه ای از گره های ثانویه داشته باشد. تمام گره های ثانویه دست نخورده باقی می مانند و زمانی که گره اصلی به روز می شود به طور خودکار به روز می شوند. و اگر گره اصلی به دلایلی از کار بیفتد، یکی از گره های ثانویه به گره اصلی تبدیل می شود.
Redis
Multi-Master Replication پشتیبانی نمی شود. هر سرور برده می تواند به عنوان یک سرور برای دیگران عمل کند. Replication در Redis منجر به مسدود کردن master یا slave نمی شود. عملیات نوشتن روی ماکت ها مجاز است. هنگامی که سرورهای اصلی و برده پس از قطع شدن دوباره به هم متصل می شوند، یک همگام سازی کامل (resync) اتفاق می افتد.
Apache Cassandra
ذخیره سازی Cassandra به گونه ای طراحی شده است که حجم زیادی از بار داده را بین چندین گره بدون خرابی سیستم مدیریت کند. معماری آن بر این واقعیت استوار است که خرابی های سیستم و سخت افزار ممکن است و اتفاق می افتد.
این ذخیره سازی با استفاده از یک سیستم توزیع شده غیرمتمرکز بین گره های همگن، که در آن داده ها در بین تمام گره ها در خوشه توزیع می شود، مشکل خرابی ها را حل می کند. همه گره های روی خوشه در هر ثانیه اطلاعات را مبادله می کنند. تغییرات متوالی هر گره فعالیت نوشتن را برای اطمینان از طول عمر داده ها ثبت می کند.
سپس داده ها ایندکس می شوند و در یک عنصر حافظه که بسیار شبیه به یک حافظه پنهان بازگشتی است، نوشته می شود. وقتی این عنصر حافظه پر است، داده ها در یک فایل داده SSTable روی دیسک نوشته می شوند. همه رکوردها به طور خودکار در کل خوشه تقسیم و کپی می شوند. در طول فرآیندی به نام فشرده سازی، فروشگاه به صورت دوره ای فایل های SSTable را ادغام می کند و اطلاعات قدیمی و شاخص های حذف داده ها را دور می ریزد.
نمایه سازی
MongoDB
نمایه سازی از اجرای پرس و جو کارآمد پشتیبانی می کند. بدون شاخص، MongoDB باید هر سند موجود در مجموعه را اسکن کند تا اسنادی را انتخاب کند که با پرس و جو مطابقت دارند. این فرآیند بسیار ناکارآمد است و نیاز به پردازش داده های زیادی دارد. برای ایجاد ایندکس در MongoDB، باید از متد ()sigureIndex استفاده کرد.
Redis
نمایه سازی در Redis با نحوه مدیریت پایگاه های داده دیگر کاملاً متفاوت است، بنابراین موارد استفاده و داده های خود شما بهترین استراتژی نمایه سازی را تعیین می کند. در اینجا چند استراتژی کلی بازیابی داده ها علاوه بر بازیابی ساده کلید/مقدار آورده شده است:
مجموعه ها را به عنوان شاخص مرتب کرد.
شاخص های واژگانی;
شاخص های جغرافیایی؛
موقعیت جغرافیایی IP؛
جستجوی متن کامل؛
شاخص های تقسیم شده
Apache Cassandra
آپاچی کاساندرا یک پایگاه داده غیرمتمرکز است که به تنهایی یک نقطه شکست را ایجاد می کند. داده ها بر اساس یکی از استراتژی ها بین گره ها توزیع می شوند. یک استراتژی رایج توزیع داده ها بر اساس مقدار کلید md5 است – یک پارتیشن کننده تصادفی. با کمک این استراتژی، نیازی نیست نگران توزیع یکنواخت داده ها بین سرورها باشید.
برای تنظیم افزونگی داده ها، باید ضریب تکرار را تنظیم کنید که مقدار کل گره ها را تعیین می کند.
ویژگی جدیدی که به Cassandra 0.7 معرفی شده است، شاخص های ثانویه است. برخلاف یک شاخص پایگاه داده رابطهای معمولی، این شاخص با مقادیر ستون مرتبط است که کلیدی برای تمام ردیفهای جدول فراهم میکند.
مقیاس پذیری
MongoDB
MongoDB با افزودن گره ها از طریق اسکریپت، مقیاس پذیری را فراهم می کند. پس از اضافه شدن گرهها، یکی از سرورها به سرور اصلی تبدیل میشود که از عملیات خواندن/نوشتن پشتیبانی میکند، و همه گرههای دیگر به بخش برده تبدیل میشوند که برای عملیات خواندن استفاده میشوند. به طور معمول یک پیکربندی از تعداد فرد سرور تشکیل شده است. در این حالت، یک سرور سرور اصلی، دیگری برده و سومی داور است. اگر سرور اصلی از کار بیفتد، داور یکی از سرورهای برده را برای جایگزینی آن تعیین می کند.
Redis
Redis یک معماری master-slave با یک توپولوژی اصلی یا خوشه ای ارائه می دهد. این اجازه می دهد تا راه حل های بسیار در دسترس که عملکرد و قابلیت اطمینان را ارائه می دهند. در صورت نیاز به تنظیم اندازه خوشه، گزینه های مختلف مقیاس بندی عمودی و افقی در دسترس هستند. در نتیجه می توانید خوشه را بر اساس نیاز خود رشد دهید.
Apache Cassandra
آپاچی کاساندرا به دلیل عدم وجود سرور مرکزی (Master Node) مزیتی دارد که خرابی آن می تواند باعث از کار افتادن کل کلاستر شود. میتوانید بدون دخالت دستی اضافی یا پیکربندی مجدد کل خوشه، گرههای جدیدی را به خوشه اضافه کنید و نسخههای Cassandra را بهروز کنید. با این حال، در عمل توصیه می شود برای حفظ کیفیت توزیع بار، کلیدها (توکن ها) برای هر گره، از جمله موارد موجود، دوباره تولید شوند. در صورت افزایش چند برابری تعداد گره ها (دو بار، سه برابر و غیره) می توان از تولید کلید برای گره های موجود اجتناب کرد.
محبوبیت
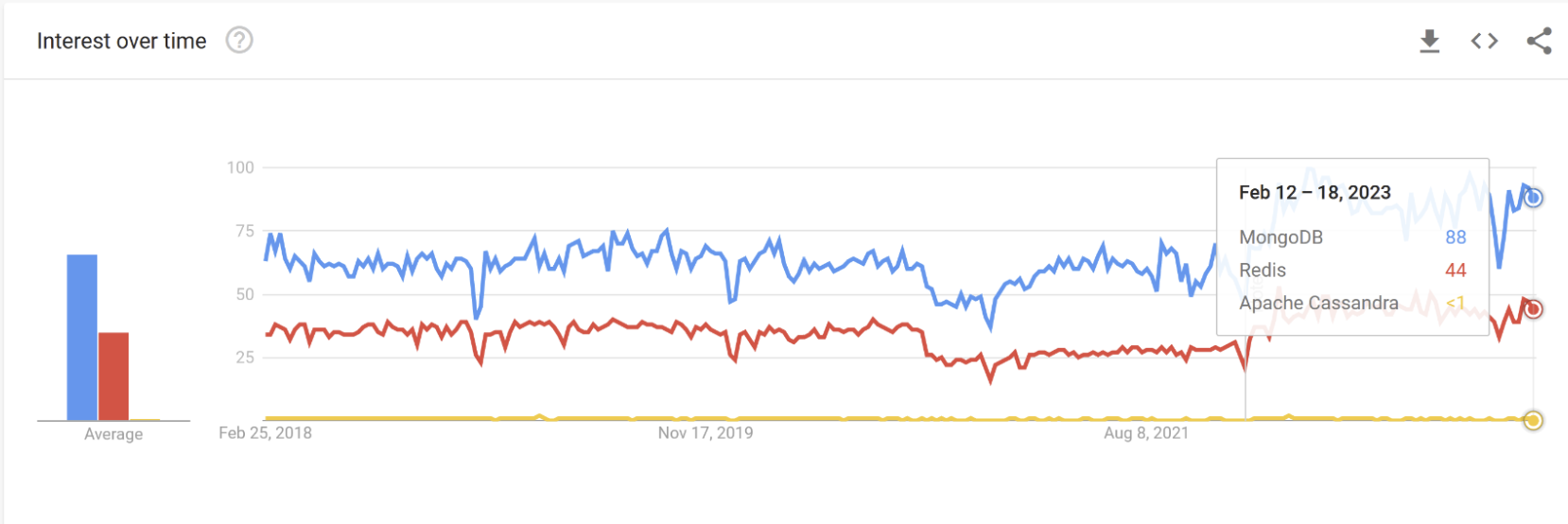
در طول یک سال گذشته، MongoDB محبوب ترین پایگاه داده در بین پایگاه های ذکر شده در بالا بود. ردیس در جایگاه دوم قرار گرفت و آپاچی کاساندرا در جایگاه آخر قرار گرفت.
انتخاب بهترین پایگاه داده NoSQL برای Node.js
| شاخص | MongoDB | ردیس | آپاچی کاساندرا |
| انواع داده ها | عدد صحیح، دوبل، بولی، رشته، آرایه، شی، نماد، تهی، مهر زمانی، حداقل/حداکثر، شناسه شی، عبارت منظم، کد، دادههای باینری، تاریخ. | رشته ها، لیست ها، مجموعه ها و هش ها، مجموعه های مرتب شده. | انواع داده های داخلی: ascii، bigint، blob، Boolean، شمارنده، اعشاری، دوبل، شناور، inet، int، متن، مهر زمانی، timeuuid، uuid، varchar، varint. مجموعه ها: لیست، نقشه، مجموعه. ایجاد شده توسط کاربر. |
| همانند سازی | سیستم ذخیره سازی یک مجموعه ماکت را نشان می دهد. دارای یک گره اولیه و همچنین می تواند مجموعه ای از گره های ثانویه داشته باشد. گره های ثانویه دست نخورده باقی می مانند، زمانی که گره اصلی به روز می شود به طور خودکار به روز می شوند و در صورت از کار افتادن گره اصلی می توانند به گره اصلی تبدیل شوند. | Multi-Master Replication پشتیبانی نمی شود. یک گره برده می تواند برای دیگران ارباب باشد. همگام سازی کامل پس از اتصال مجدد Slave و Master. | پایگاه داده از یک سیستم توزیع شده غیرمتمرکز بین گره های همگن استفاده می کند، که در آن داده ها بین تمام گره های خوشه توزیع می شود. در صورت خرابی سیستم به ذخیره داده ها کمک می کند. |
| نمایه سازی | با تسهیل و سرعت بخشیدن به روند جستجو، عملکرد پایگاه داده را بهبود می بخشد. | یک استراتژی نمایه سازی ایجاد شده توسط کاربر. بسته به مورد استفاده متفاوت است. | از شاخص های ثانویه پشتیبانی می کند. |
| مقیاس پذیری | با افزودن گره ها از طریق اسکریپت، مقیاس پذیری را فراهم می کند. | گزینه های مختلف مقیاس بندی عمودی و افقی در دسترس هستند، بنابراین می توانید خوشه خود را رشد دهید. | آپاچی کاساندرا هیچ گره اصلی ندارد، بنابراین می توانید آن را به سرعت به روز کنید. |
| محبوبیت | محبوب ترین | دومین محبوب ترین | کم محبوب ترین |
نتیجه
همانطور که در ابتدای مقاله نوشتیم، انتخاب پایگاه داده برای پروژه Node.js بستگی به نوع وظایفی دارد که باید حل کنید. برخی از توسعه دهندگان ترجیح می دهند از پایگاه داده NoSQL استفاده کنند، برخی دیگر ترجیح می دهند از یک پایگاه داده SQL استفاده کنند. با این حال، این فقط یک موضوع عادت و سلیقه است.
این مقاله انواع پایگاه داده SQL و NoSQL را تشریح کرده و برای هر کدام مثالهای عملی آورده است. اگر در مورد اینکه کدام نوع پایگاه داده را برای پروژه خود انتخاب کنید شک دارید، بهتر است با یک شرکت توسعه معتبر همکاری کنید. Bamboo Agile به طور فعال و با موفقیت از انواع پایگاه داده SQL و NoSQL در پروژه های خود استفاده می کند.
منبع
